LiteSpeed is a fantastic product despite its premium cost, it’s worth the extra cash investment.
We owe much of our success at NameHero to our high-speed infrastructure that is optimized for blazing fast performance. This makes our customers’ websites load ridiculously fast when compared to the more traditional hosting packages offered by the “Big Box” competitors around the web hosting industry. Our speed comes partly from the enterprise-grade server hardware that we deploy, but just as important is how we leverage LiteSpeed Web Server in all our servers. If your site is hosted at NameHero, you can bet that it’s running on LiteSpeed rather than the more traditional LAMP Stack solutions which rely on Apache Web Server.
- Does website speed really matter?
- What is LiteSpeed?
- What is Apache?
- Okay, but how is LiteSpeed any different?
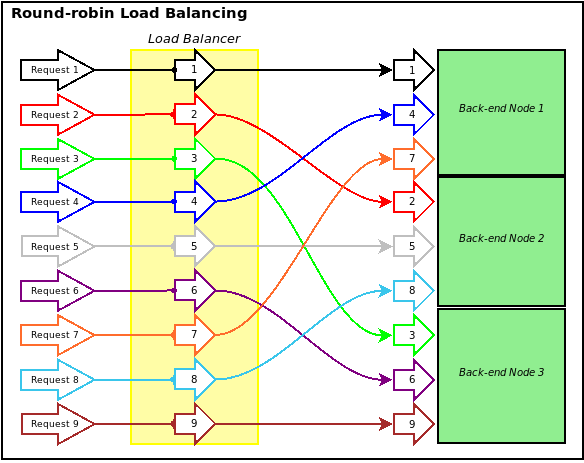
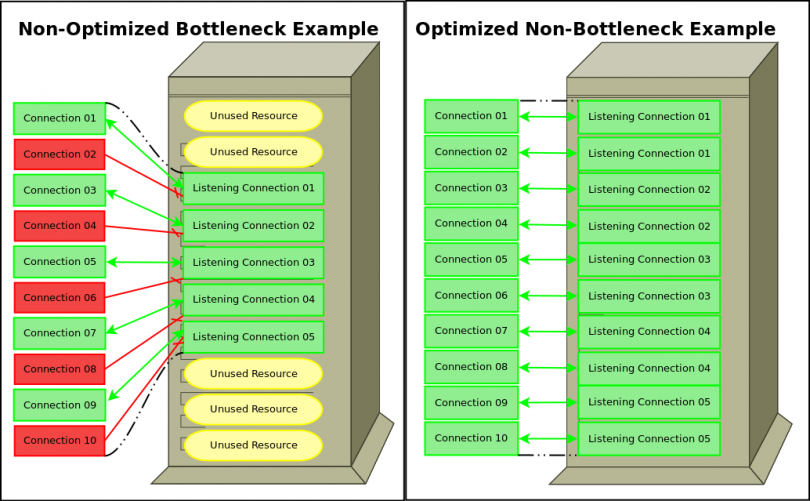
- What are the main benefits of LiteSpeed versus Apache
- Benchmarks – LiteSpeed vs. Apache Web Server
- LiteSpeed WordPress Cache
To read the full article, head on over to the NameHero Blog by clicking the image below.


/link